Com o aumento da necessidade por espaço de armazenamento de dados, a Microsoft criou uma solução aparentemente simples de gerenciamento lógico de dados – a deduplicação de dados – com o objetivo principal de otimização de espaço em servidores de grandes empresas e data centers. Apesar de parecer simples, o seu funcionamento é bastante complexo e no artigo de hoje iremos explorar mais esse assunto.
O que é dedup de dados? (Data Deduplication)
A deduplicação de dados é um sistema nativo do Windows Server 2012 que gerencia os dados duplicados no sistema, servidor ou storage. O objetivo do gerenciamento é detectar dados repetidos e eliminá-los. Com isso, há uma disponibilidade maior de espaço e, consequentemente, uma redução de custos por armazenagem de dados existentes. Além disso, há o benefício de otimização do tempo em relação a procura manual de arquivos repetidos.
Média de economia de espaço em ambientes de pequeno e grande porte

Estes dados foram disponibilizados pela própria Microsoft e é possível dimensionar o impacto do dedup na redução de espaço de cada conteúdo. A duplicação de dados acontece bastante em ambientes com servidor compartilhado por setores e equipes devido a necessidade de compartilhamento diário de informações em um mesmo ambiente. Nesses casos, além do dedup ser uma ótima solução, temos também a possibilidade de utilizar o sincronismo para o uso de arquivos compartilhados em nuvem quando estes forem editáveis no ambiente online.
Em quais situações o DEDUP é usado?
O dedup é usado, geralmente, em servidores de arquivos, mais conhecidos no meio da TI como “File Server”. Dessa forma, são servidores ou até mesmo storages com arquivos simples, em geral, XLSX, DOCX, JPEG, PDF. Ou seja, arquivos intrínsecos à todas as empresas, independentemente do porte.
Como funciona o processo de eliminação de dados duplicados na prática
O processo é baseado em procurar as mesmas entradas, inclusive, os atributos. Sendo assim, todas essas informações já estão no sistema de gerenciamento de dados do Windows, chamado de MFT (falaremos sobre isso em breve). Após essa identificação, o algoritmo do DEDUP é capaz de identificar qual é o arquivo mais atual e seguir com a eliminação de todos os dados duplicados no ambiente de modo geral. Veja as imagens abaixo:
Verificação de arquivos

Divisão

Identificação (tipo)
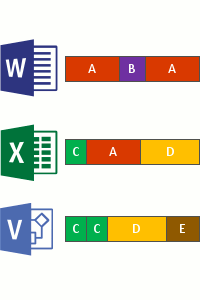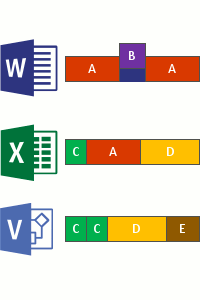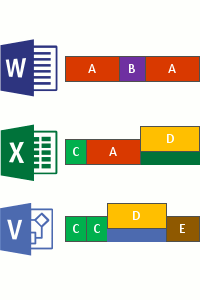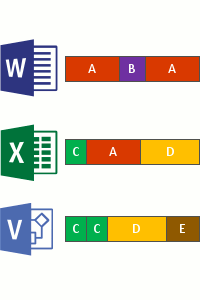
Inserção no repositório (possível configurar compactação)
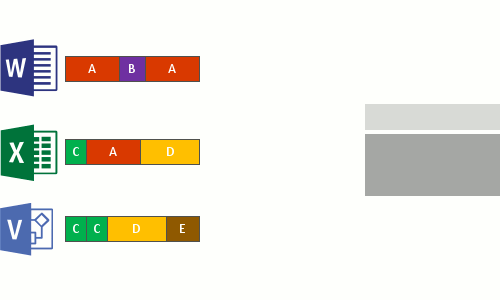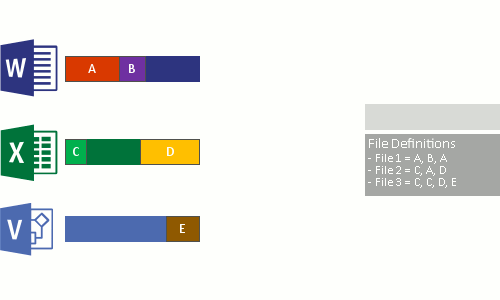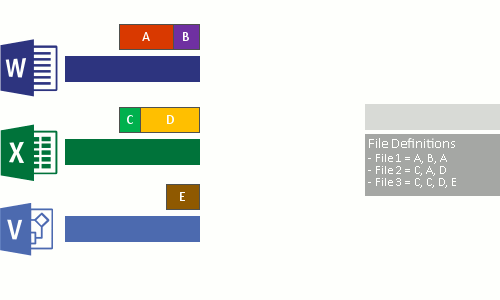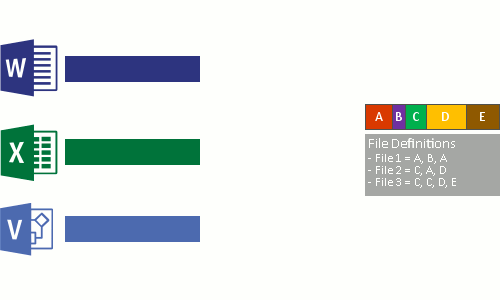
Substituição pelos arquivos já otimizados
Conclusão
A deduplicação de dados é uma ferramenta poderosa, versátil e com grandes ganhos. Porém, sua má gestão e otimização incorreta podem gerar corrupção de dados, às vezes, até mesmo a nível sistêmico de corrupção de estrutura, afetando os dados de uma forma geral.
Contudo, não se preocupe, a HD Doctor possui tecnologia capaz de reverter qualquer problema de perda de dados gerado pelo deduplicação de dados. Durante mais de 20 anos, desenvolvemos tecnologia de engenharia reversa, capaz de mitigar dados perdidos, recuperar arquivos apagados, recuperar dados corrompidos, indisponíveis ou com vírus.
Com índice de 95% de sucesso no casos recebidos e mais de 75.000 clientes satisfeitos em todo o Brasil, a HD Doctor é referência em recuperação de HD, SSD, cartão de memória, recuperação de servidor e dispositivos criptografados por ransomware. Além disso, garantimos total sigilo com suas informações, conforme explicitado em nossa política de privacidade, e estamos em conformidade com a LGPD – Lei Geral de Proteção de Dados Pessoais.
Finalizando, se tem dúvidas de como recuperar dados de HD, processo de recuperação de dados de servidores, etc., entre em contato com um de nossos especialistas pelo 0800 607 8700. Atendimento especializado 24H.
Não deixe de seguir a HD Doctor nas redes sociais: Instagram, Facebook e LinkedIn